


Discover Voxtral TTS: Mistral’s Cutting-Edge Open-source Text-to-Speech Innovation
Mistral, a pioneering AI company based in France, has introduced Voxtral TTS, an advanced open-source text-to-speech model designed to revolutionize voice AI across multiple sectors. This breakthrough technology equips organizations with the tools to build sophisticated voice agents that enhance customer interaction adn boost sales performance, positioning Mistral as a strong contender alongside industry leaders such as elevenlabs, Deepgram, and OpenAI.
Extensive Language Support for Global Applications
Voxtral TTS offers robust support for nine languages including English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. This extensive multilingual capability allows companies to deploy voice solutions that effectively engage diverse international markets without language barriers.
Efficient Architecture Designed for Portable devices
Pierre Stock, Mistral’s vice president of science operations highlights the model’s streamlined design: “Our clients demanded a speech synthesis system optimized for edge devices like smartwatches and smartphones. We engineered a lightweight yet powerful speech model that delivers state-of-the-art results at considerably lower computational costs compared to existing options.” This compact framework ensures smooth operation on laptops and mobile gadgets while maintaining premium audio fidelity.
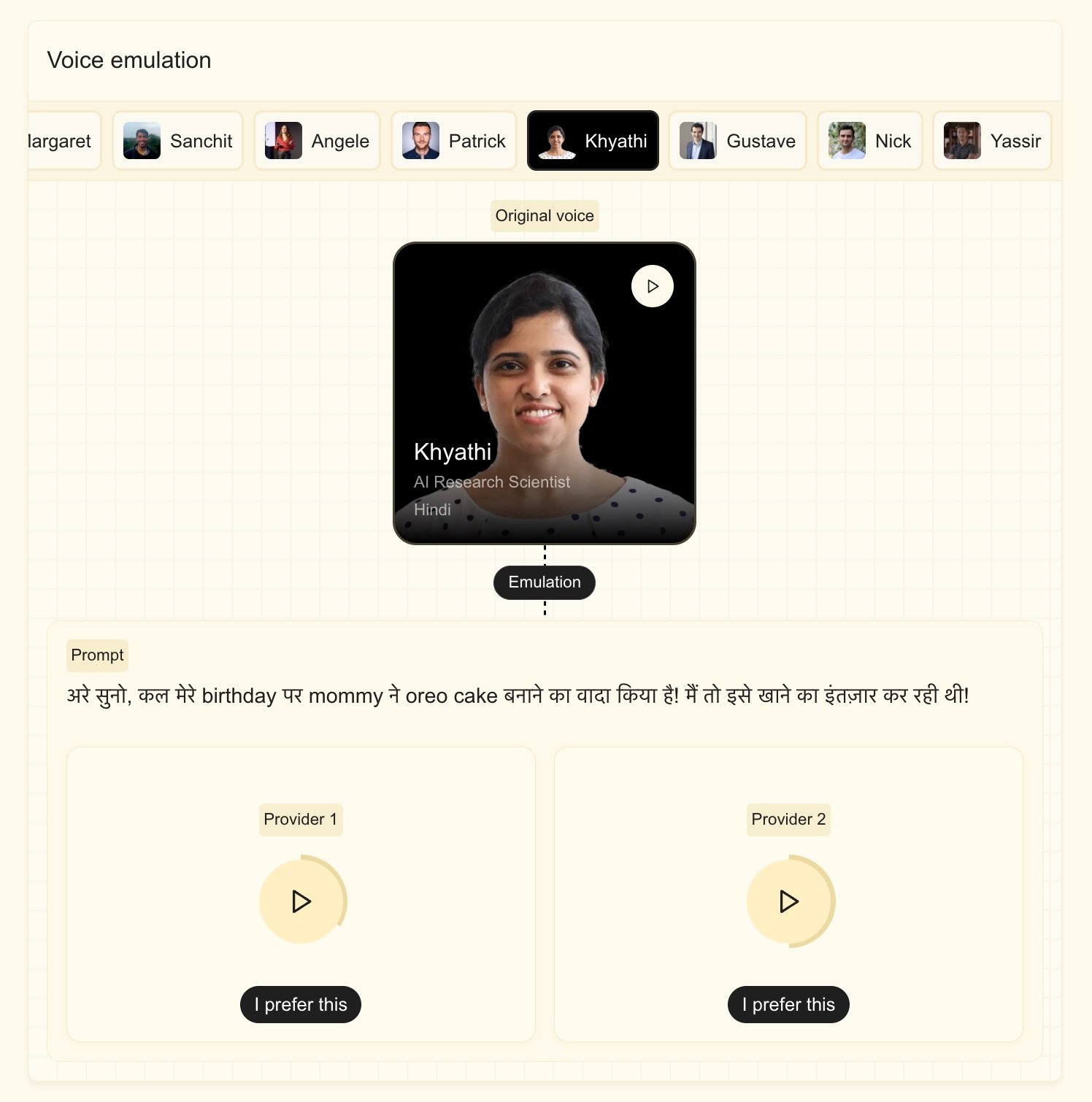
Authentic Voice Cloning with Minimal Audio Input
The Voxtral TTS system can generate personalized voices from under five seconds of recorded audio.It adeptly captures subtle vocal nuances such as accents, intonation patterns, inflections, and natural speech variations-key elements in producing lifelike digital voices. Built on the Ministral 3B architecture, it seamlessly transitions between languages while preserving distinct vocal identities, making it ideal for applications like film dubbing or live multilingual translation services.
Designed for Instantaneous Conversational Experiences
The platform excels in responsiveness-a critical factor in interactive environments. Its time-to-first-audio (TTFA) is approximately 90 milliseconds when processing around 500 characters over ten seconds of speech. Moreover,a real-time factor (RTF) of 6x enables generating ten seconds of audio within roughly 1.6 seconds.This rapid turnaround supports fluid conversations essential in virtual assistants or customer service bots.
A Comprehensive Ecosystem Poised for Expansion
This launch builds upon earlier releases by Mistral this year featuring transcription models tailored both for high-volume batch tasks and low-latency streaming scenarios. The company envisions creating an integrated multimodal platform capable of handling diverse inputs-including audio streams,text data,and images-while delivering flexible outputs.“A unified agentic system supporting multiple input formats greatly enriches information depth,” Stock noted.“This strategy empowers businesses to develop more dynamic interactive agents.”
The Edge Computing Advantage: Flexibility Meets Control
Mistral’s dedication to open-source innovation grants enterprises exceptional freedom to customize voice models according to their unique requirements-a significant edge over proprietary solutions that often restrict adaptability. By facilitating scalable fine-tuning,organizations can craft personalized user experiences while optimizing deployment expenses effectively.


{kind=link}