


DeepSeek V3.2-exp: Advancing efficient AI Processing for Extended Contexts
Transforming Inference Efficiency with Innovative Sparse Attention
The latest iteration of DeepSeek’s experimental AI, V3.2-exp, introduces a groundbreaking approach designed to substantially lower inference costs when handling long input sequences. Central to this breakthrough is the deepseek Sparse Attention technique, which smartly prioritizes and processes relevant data segments within extensive contexts.
How Sparse Attention Operates in DeepSeek V3.2-exp
This technology employs a two-tiered filtering system: first, a rapid “lightning indexer” scans the entire context window to pinpoint the most pertinent sections; next, a detailed token selector hones in on critical tokens within those chosen segments for focused attention processing. This layered strategy allows the model to sustain high accuracy over lengthy inputs while drastically cutting down computational overhead.
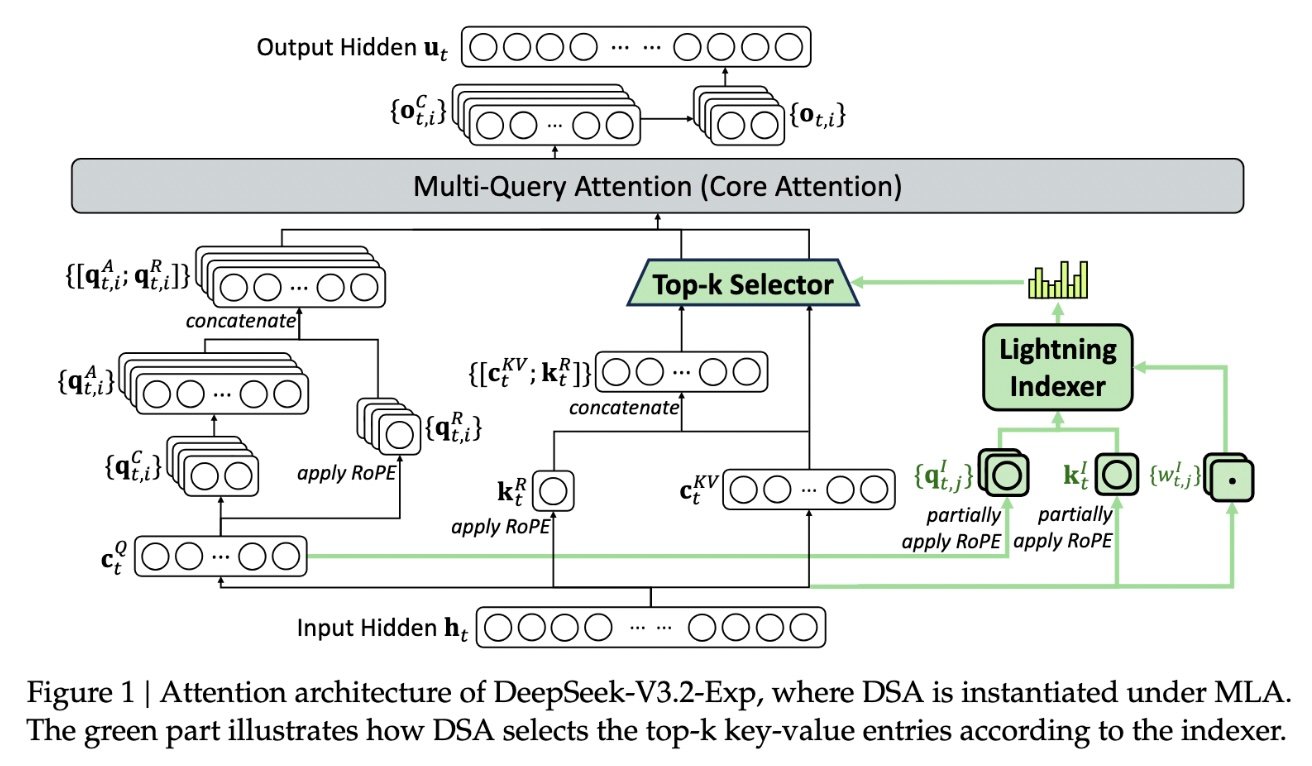
Significant Gains in cost Reduction and Model Performance
Preliminary testing indicates that API expenses related to tasks involving large context windows can be reduced by nearly 50%. Although ongoing evaluations aim to confirm these findings across various domains, this open-weight model is accessible for independent scrutiny and experimentation on Hugging Face.
Easing Server Resource Strain in Large-Scale AI Systems
The challenge of managing server load during inference has been a major bottleneck for deploying transformer models at scale. By optimizing how attention mechanisms allocate computational resources-focusing only on essential tokens-DeepSeek’s sparse attention method offers an adaptable solution that balances efficiency with precision. This proves especially valuable in applications like multi-turn conversational agents or extensive document summarization where inputs often exceed thousands of tokens.
A Distinctive Approach from China’s AI Innovator DeepSeek
Differentiating itself from global competitors primarily chasing larger-scale models, DeepSeek emphasizes cost-effective training and deployment strategies rooted in practical efficiency rather than sheer size alone. Earlier releases such as their R1 model showcased reinforcement learning techniques implemented at substantially lower costs compared to many Western alternatives-though it did not immediately disrupt industry norms as some expected.
The introduction of sparse attention may quietly influence international efforts by demonstrating how operational budgets can be optimized without compromising advanced capabilities.
The Broader Implications for Transformer Model Evolution
- sustainability: Reducing energy consumption aligns with increasing environmental concerns tied to massive AI infrastructures worldwide.
- User Inclusivity: Lower operational costs could enable startups and academic institutions globally easier access to sophisticated language models previously limited by expense barriers.
- Diverse Use Cases: Improved handling of extended contexts benefits sectors such as legal analysis or personalized education platforms requiring deep comprehension over long documents or dialogues.
“Sparse attention innovations represent vital progress toward making powerful language models more scalable and affordable across industries.”
An Open Invitation for Collaborative Advancement and Validation
The release of V3.2-exp as an open-weight resource fosters community-driven testing and iterative enhancement efforts among researchers worldwide. As developers integrate this technology into diverse workflows-from natural language understanding tools to complex multi-document reasoning systems-we anticipate accelerated advancements yielding even more efficient architectures tailored for specialized real-world applications.


{kind=link}