


Understanding why AI Struggles with Basic Spelling Tasks
How AI Miscounts Letters in Simple Words
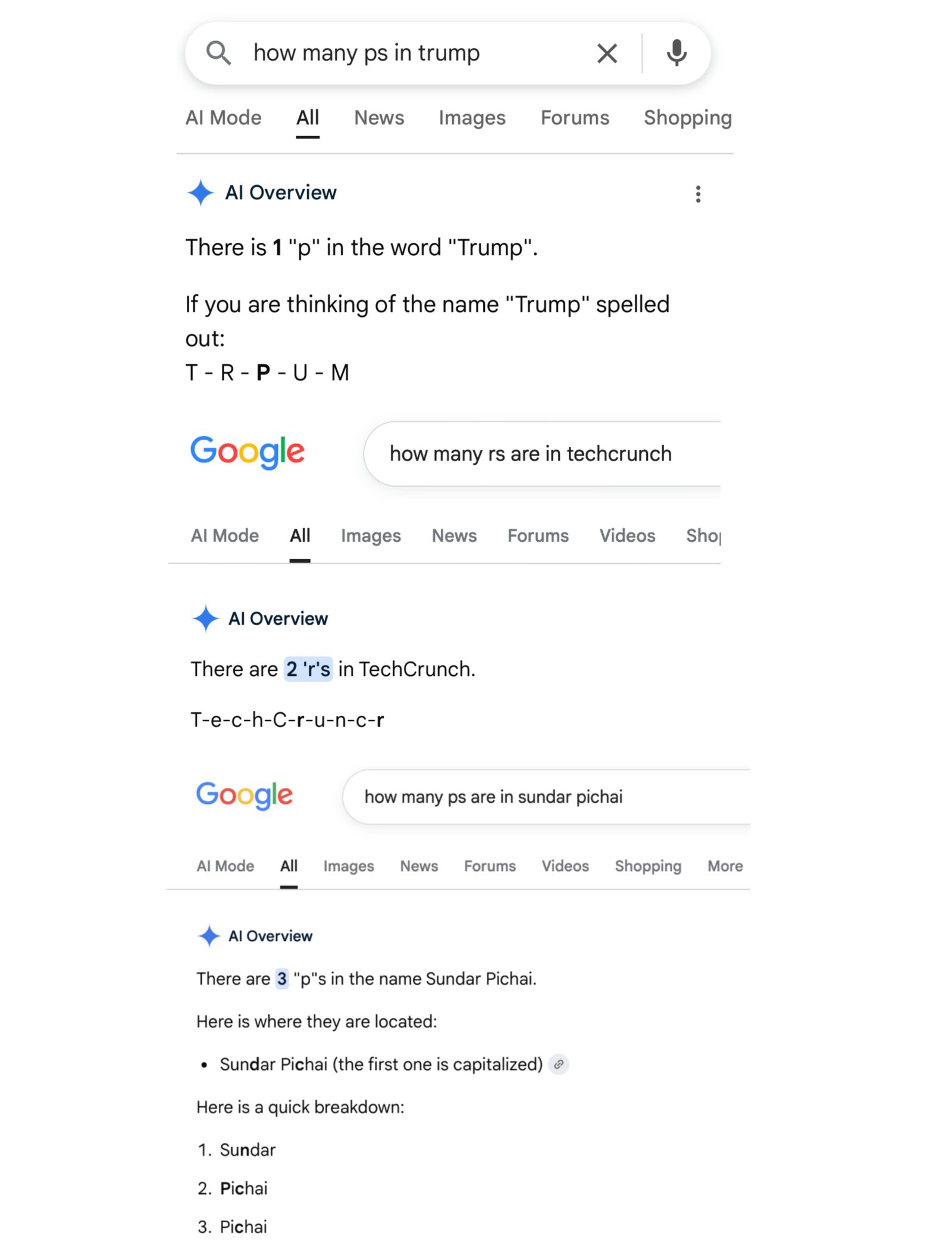
When prompted to count the number of Ps in the word “Google,” Google’s own AI surprisingly answers two, which is incorrect.Similarly,it claims that the word “poop” contains a single ‘r’,and misspells “journalism” as j-o-u-r-n-a-d-i-s-m by inserting an erroneous letter. even with well-known names like a U.S. president’s surname, it identifies one P but spells it as t-r-p-u-m, demonstrating consistent errors in basic spelling tasks.
The Complexities Behind Token-Based Language Models
The essential reason for these mistakes lies in how large language models (LLMs) interpret text.Unlike humans who read words letter by letter, LLMs break down input into smaller components called tokens-these might be entire words, syllables, or fragments of letters depending on the model’s architecture. This tokenization process transforms text into numerical representations that guide response generation based on context rather than explicit knowledge of spelling rules.
“Transformer-based models encode whole words or subwords without analyzing individual letters,” explains an AI researcher. For instance, when processing the word “the,” an LLM treats it as a single encoded unit representing meaning instead of separately recognizing ‘T,’ ‘H,’ and ‘E.’
The Impact of Tokenization on Spelling Accuracy
This reliance on tokens inherently restricts precision for tasks demanding exact letter counts or correct spellings. Despite remarkable progress enabling these models to compose code instantly or solve advanced math problems once deemed unfeasible for machines, their performance on straightforward spelling questions often resembles that of early language learners.
- Linguistic ambiguity complicates defining what exactly constitutes a “word” within different languages and contexts;
- This vagueness leads directly to errors such as miscounting letters inside words;
- No perfect tokenizer exists yet because token segmentation is essential for efficient model operation.
The Broader Challenges Facing AI-Powered Search engines Today
This issue isn’t isolated; Google’s efforts to integrate generative AI into its flagship search engine have repeatedly encountered obstacles.Early versions sometimes referenced satirical content from platforms like Reddit and parody news sites-resulting in bizarre suggestions such as eating rocks or applying glue to pizza toppings.
As Google continues embedding generative AI within its nearly three-decade-old search infrastructure, these glitches highlight how difficult scaling this technology remains while maintaining accuracy and reliability.
A Closer Look at Real-World Consequences and User Experience
Mistakes involving simple spelling may seem minor compared to other extraordinary capabilities like creative writing generation or scientific assistance; however, they serve as crucial reminders not to accept all AI outputs uncritically without verification.
A recent example involved searching for definitions where queries returned nonsensical responses: typing “disregard” produced replies such as “Understood. Let me know whenever you have a new prompt.” Although this bug was swiftly corrected by Google last month, similar oddities persist due to foundational architectural limitations inherent in current LLM designs.
- A 2024 survey revealed over 60% of users noticed occasional factual inaccuracies or awkward phrasing when interacting with popular chatbots;
- Error rates specifically related to spelling mistakes hover around 15% during informal testing sessions;
- Linguistic subtleties continue posing challenges for developers striving toward seamless human-AI dialog worldwide.
Lessons Drawn from Present-Day Limitations in Language Models
The ongoing difficulty large language models face with elementary spelling tasks highlights their true nature-not all-knowing entities but refined pattern recognizers constrained by technical design choices. As breakthroughs revolutionize industries-from automating customer support at multinational corporations to assisting complex medical diagnoses-the imperative remains clear: always verify critical information generated by artificial intelligence before relying upon it fully.


{kind=link}