


DeepSeek Launches Next-Generation Large Language Models with unrivaled Scale and Efficiency
Revolutionizing AI: The DeepSeek V4 Series Debuts
DeepSeek, a trailblazer in Chinese artificial intelligence, has introduced two cutting-edge large language models: DeepSeek V4 Flash and DeepSeek V4 Pro. Thes new releases mark a ample advancement over the previous V3.2 generation, featuring state-of-the-art architectural improvements aimed at enhancing performance in complex reasoning and software progress tasks.
Unprecedented Model Sizes Backed by Innovative Design
The flagship model, V4 Pro, impressively incorporates 1.6 trillion parameters, with 49 billion actively engaged during inference processes. This parameter count eclipses other notable open-weight models such as Moonshot AI’s Kimi K 2.6 (1.1 trillion parameters) and MiniMax’s M1 (456 billion), effectively doubling the scale of DeepSeek’s earlier version.
the more streamlined V4 Flash, equipped with 284 billion parameters and activating 13 billion at any given time, strikes an optimal balance between computational demand and operational capability.
selectively Activated Experts for Cost-Effective Computation
A key innovation lies in thier mixture-of-experts architecture that dynamically engages specific subsets of parameters tailored to each task’s requirements. This selective activation dramatically lowers inference costs while preserving high accuracy levels. Notably, these models support context windows extending up to one million tokens per input prompt-enabling them to analyse entire codebases or lengthy documents within a single query seamlessly.
Performance Benchmarks: Surpassing Expectations Amidst Fierce Competition
The deepseek V4 Pro-Max achieves outstanding results on reasoning benchmarks, outperforming many open-source rivals as well as some proprietary leaders like OpenAI’s GPT-5.2 and Google Gemini 3.0 Pro in targeted evaluations.
Coding assessments reveal that both versions deliver programming task outcomes comparable to OpenAI’s GPT-5.4 series-demonstrating formidable capabilities in software development contexts.
“Our latest design narrows the gap with top-tier closed-source systems while offering superior efficiency,” representatives from DeepSeek emphasize.
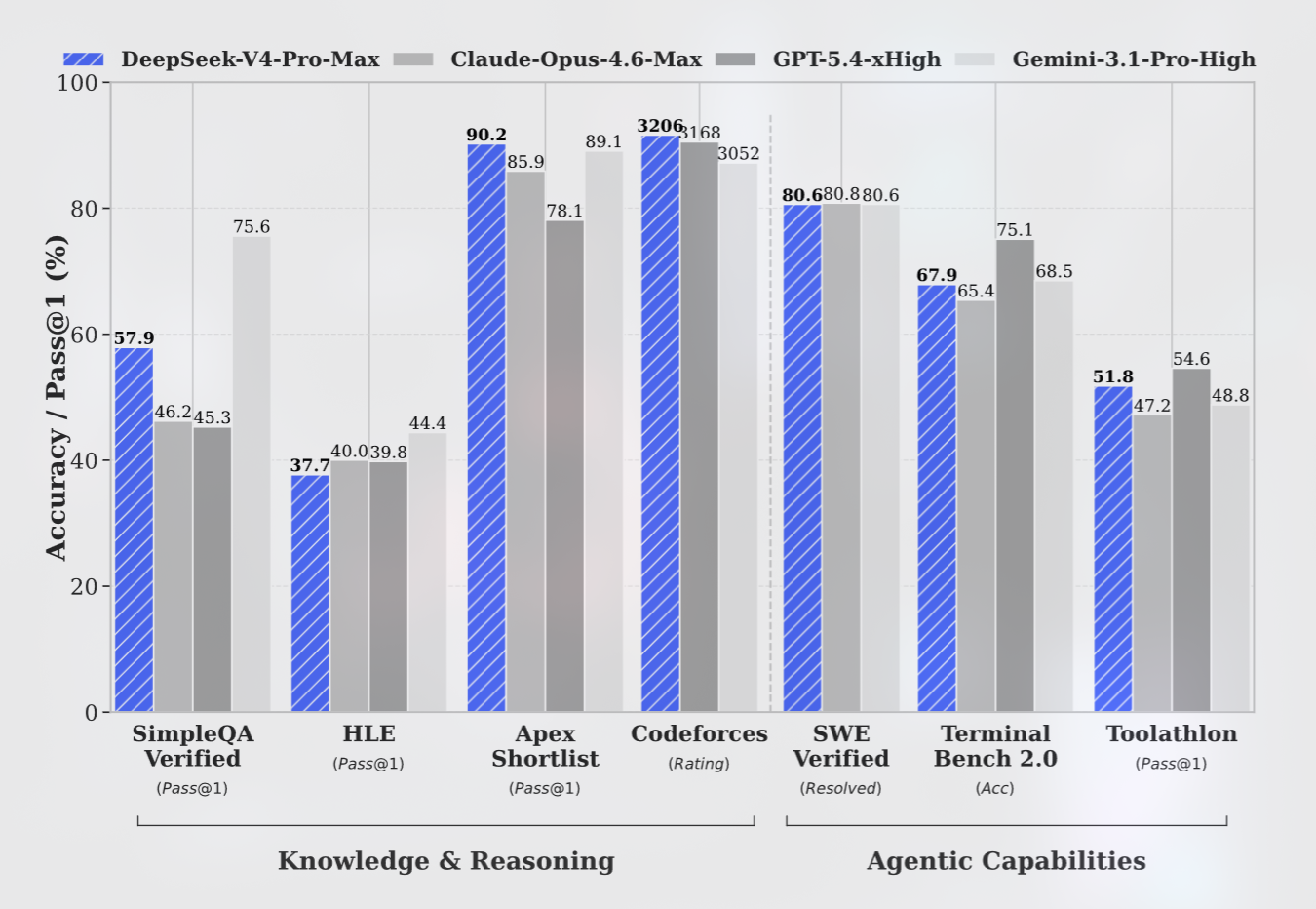
However, when tested on knowledge-based queries requiring up-to-date factual information, these models currently trail behind leading-edge offerings such as openai’s GPT-5.4 and Google Gemini 3.1 Pro-reflecting an estimated developmental lag of three to six months relative to the most advanced benchmarks available today.
A Focus on Text Processing Amidst Growing Multimedia Demands
An vital limitation is that both versions presently handle only text inputs and outputs; they do not yet process audio, video, or image data like several competing closed-source platforms do-a factor that may influence adoption depending on specific submission needs across industries increasingly reliant on multimodal AI solutions.
Affordable Pricing Models Deliver Competitive Advantages
- V4 Flash pricing:
- $0.14 per million input tokens;
- $0.28 per million output tokens;
- V4 Pro pricing:
- $0.145 per million input tokens;
- $3.48 per million output tokens;
- This pricing structure undercuts comparable offerings from GPT-5.x Nano/Mini variants, Google Gemini flash/pro tiers, Anthropic’s Claude Haiku/Opus releases-all while maintaining competitive performance metrics suitable for enterprise deployment.
Navigating Intellectual Property challenges Facing Chinese AI Labs
This proclamation emerges amid intensified scrutiny regarding alleged intellectual property infringements involving Chinese AI organizations accused by U.S.-based entities of replicating proprietary technologies through extensive proxy networks-a controversy specifically implicating labs including DeepSeek for purportedly “distilling” competitor model capabilities without authorization or licensing agreements.
The Road Ahead: Expanding Capabilities Beyond Text-Centric Models
- The ongoing development trajectory suggests these models will rapidly close performance gaps against global leaders within approximately six months.
- If multimedia modalities such as audio and visual processing are integrated alongside existing text functions soon,
a wider array of sectors-from healthcare diagnostics to autonomous vehicles-could reap critically importent benefits.
A Milestone Toward Democratizing Ultra-Large Language Modeling Technology Globally
The launch of the DeepSeek V4 family represents a critical step toward making ultra-large-scale language modeling accessible beyond Western technology ecosystems by combining unprecedented parameter counts with cost-effective deployment strategies tailored for enterprise applications demanding deep contextual understanding across massive datasets or extensive code repositories worldwide.


{kind=link}